
Zahra Shahrooei
PhD Student, Mechanical Engineering Department, Rochester Institute of Technology, NY, US
Multi-fidelity Bayesian optimization framework for falsification of autonomous driving systems
We propose a multi-fidelity Bayesian optimization framework for falsification of control systems, to reduce simulation cost while enhancing counterexample detection.
Why is Falsification Critical in Safety-Critical Systems?
The validation and verification of controllers are essential in safety-critical systems, where failures can lead to catastrophic consequences. Simulation-based testing is a critical part of this process, with the goal of identifying potential failures before deployment in real-world. Falsification is a specific search-based testing procedure designed to systematically find system inputs, known as counterexamples, that cause the system to violate predefined safety specifications.
This search for counterexamples can be formally shown as a global optimization problem. We define a robustness metric, which quantifies the degree to which a system’s trajectory, generated from an environmental input, satisfies a given safety specification. A positive robustness value indicates that the specification is met, while a negative value signifies a violation. The falsification goal is to find an environmental input that leads to the most significant safety violation, i.e., the most negative robustness value. For complex, black-box control systems where the relationship between inputs and the robustness score is unknown, this optimization is particularly challenging.
Bayesian Optimization for Falsification in Safety-Critical Systems
To solve this black-box optimization problem efficiently, one can use Bayesian optimization (BO). BO is a sample-efficient methodology ideal for optimizing functions that are expensive to evaluate. It operates by building a probabilistic surrogate model of the unknown objective function and using that model to intelligently select the next points to evaluate. The framework has two key components:
- Surrogate Model: We use a Gaussian Process (GP) to model the unknown robustness function. A GP is a non-parametric model that defines a prior distribution over functions. After observing a set of input-output pairs, the GP is updated to form a posterior distribution that provides not only a mean prediction for any new input e but also a measure of uncertainty about that prediction.
- Acquisition Function: To decide the next input to test, BO optimizes an acquisition function. This function uses the GP’s predictions and uncertainties to quantify the utility of evaluating a particular point. There are different acquisition functions in literature. Common choices include Probability of Improvement, which maximizes the chance of finding a better value, and Expected Improvement, which considers the magnitude of potential improvements.
Challenge: While BO is sample-efficient, its application in falsification is often hindered by a critical challenge: the high computational cost of full-fidelity simulators. To obtain an accurate robustness value, one must typically execute a detailed, high-fidelity simulation of the control system. These simulations can be extremely time-consuming, sometimes taking hours or even days for a single run. Consequently, performing the dozens or hundreds of evaluations required for a BO-based search can become prohibitively expensive, which limits the practical feasibility of thorough safety validation for complex systems.
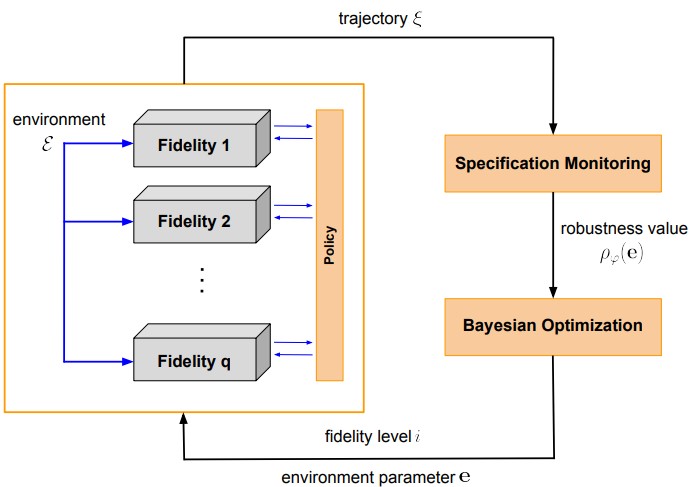
Overview of Multi-fidelity Bayesian Optimization for falsification
Multi-Fidelity Bayesian Optimization for Falsification of Control Systems
To address the prohibitive computational cost, we propose a multi-fidelity Bayesian optimization (MFBO) framework for falsification. Multi-fidelity BO has been extensively used in fields like engineering design and hyperparameter optimization to accelerate expensive tasks by leveraging cheaper, approximate models. Our work is the first to adapt this powerful technique to the specific problem of falsifying closed-loop control systems.
The core idea is to accelerate the search for counterexamples by integrating information from multiple simulators with varying levels of accuracy and computational cost. Instead of relying exclusively on the expensive full-fidelity simulator, our approach strategically leverages cheaper, lower-fidelity models to explore the input space more rapidly and guide the search toward promising regions. Our MFBO framework is designed to:
- Model Inter-Fidelity Relationships: We establish a statistical relationship between the robustness values obtained from different fidelity levels using a multi-output GP. Specifically, we use an auto-regressive model where the output of a higher-fidelity simulator is modeled as a function of the next-lower fidelity’s output plus a learned discrepancy term.
- Make Cost-Aware Decisions: The acquisition function is modified to decide not only what input to test next, but also at which fidelity level to test it. We use multi-fidelity version of Entropy search, which is an information-theoretic acquisition function that selects the point expected to yield the most information about the location of the global minimum. The choice of fidelity is made by maximizing the information gain per unit of computational cost.
- Systematically Determine Costs: A key contribution of our work is a systematic method for assigning the relative simulator costs. Rather than relying on manually predefined constants, which can degrade performance, we compute these costs based on measurable parameters: the average simulation time and the output similarity (measured using cosine similarity) between trajectories from different simulators. This creates a more adaptive and realistic cost model.
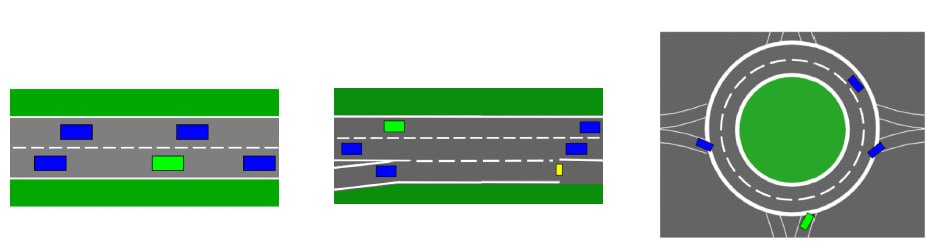
Autonomous Driving Scenarios: Highway, Merge, and Roundabout
Generating Testing Scenarios for Autonomous Driving
We evaluated the performance of our proposed framework on several benchmarks from OpenAI Gym, including complex autonomous driving scenarios (Highway, Merge, and Roundabout). We compared our two- and three-fidelity BO approaches against a suite of baselines, including:
- Standard BO run exclusively on the high-fidelity simulator.
- Standard BO run on the low- and middle-fidelity simulators independently.
- Other state-of-the-art BO extensions that rely on high-fidelity data, namely TuRBO (Trust Region BO) and πBO (Prior-Informed BO).
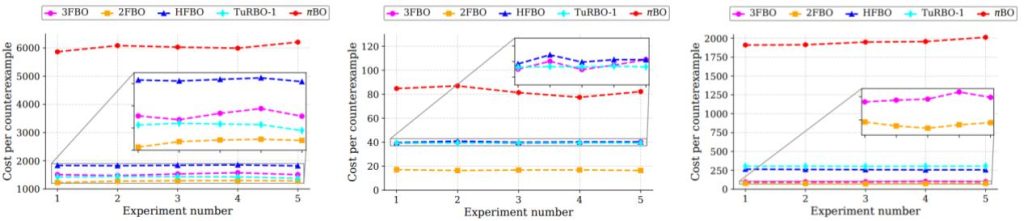
Cost per counterexample for highway, merge, and roundabout driving scenarios
The results demonstrate that our multi-fidelity frameworks are significantly more computationally efficient at detecting counterexamples. Across the different scenarios, both two- and three-fidelity BO consistently found safety violations at a lower computational cost than the baselines that rely solely on full-fidelity simulations. For more details, see MFBO1 and MFBO2.