Zahra Shahrooei
PhD Student, Mechanical Engineering Department, Rochester Institute of Technology, NY, US
Enhancing Sample Efficiency in Deep Reinforcement Learning with Wasserstein Barycenter Soft Actor-Critic
Sample Efficiency in Continuous Control
Deep off-policy actor-critic algorithms often suffer from poor sample efficiency. In most of these approaches, the agent relies on heuristic exploration methods such as injecting random noise or maximizing simple entropy, which are undirected and inefficient exploration strategies. Hence, in these algorithms the agent requires a massive number of interactions with the environment to learn useful behaviors, particularly in scenarios where rewards are sparse or the state-space is high-dimensional. Addressing this inefficiency is critical for deploying reinforcement learning in real-world applications where data collection is expensive.
Wasserstein Barycenter Soft Actor-Critic (WBSAC):
To address the problem of sample inefficiency, we introduce a new framework called Wasserstein Barycenter Soft Actor-Critic (WBSAC). Rather than relying on a single policy with random noise, our method employs a dual-actor architecture. We train a pessimistic actor, which focuses on safety and exploitation by maximizing a lower bound of the Q-function, and an optimistic actor, which is driven by uncertainty to explore regions where the critic estimates diverge. This distinction allows the agent to separate the goal of robust learning from the goal of discovering new, potentially high-reward policies.
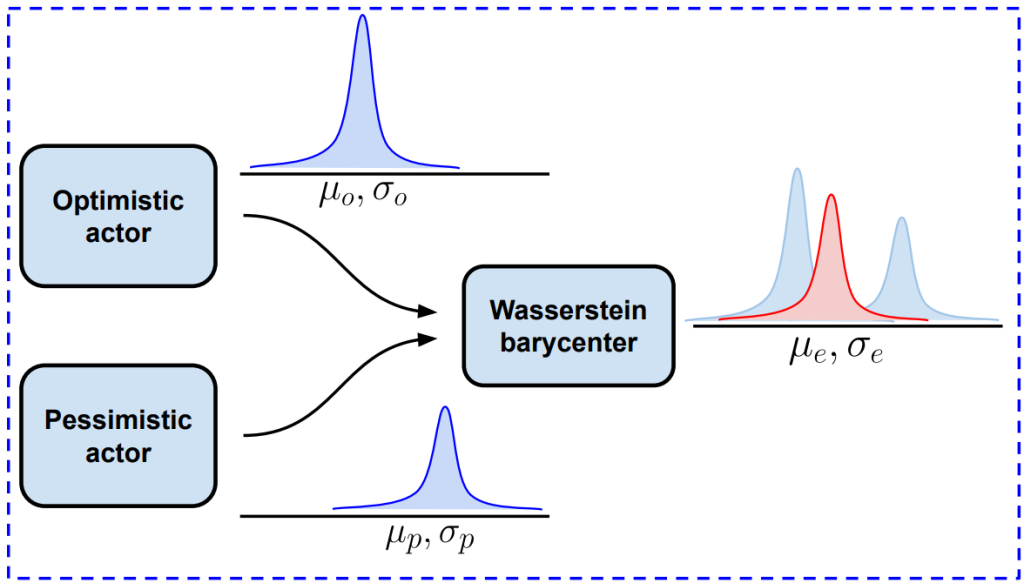
WBSAC’s exploration policy
The main novelty of WBSAC is in how we combine these two distinct behaviors. We make use of the Wasserstein barycenter, a concept from optimal transport theory, to geometrically blend pessimistic and optimistic policies into a single exploration policy. This approach allows us to dynamically control the degree of exploration. Early in training, the agent behaves conservatively (pessimistic); as training progresses, we mathematically shift the barycenter weights to incorporate more optimistic behavior. This results in a “directed” exploration strategy that is significantly more sample-efficient than standard random exploration, as it guides the agent intelligently toward informative areas of the action space without destabilizing the learning process.
Evaluation and Results
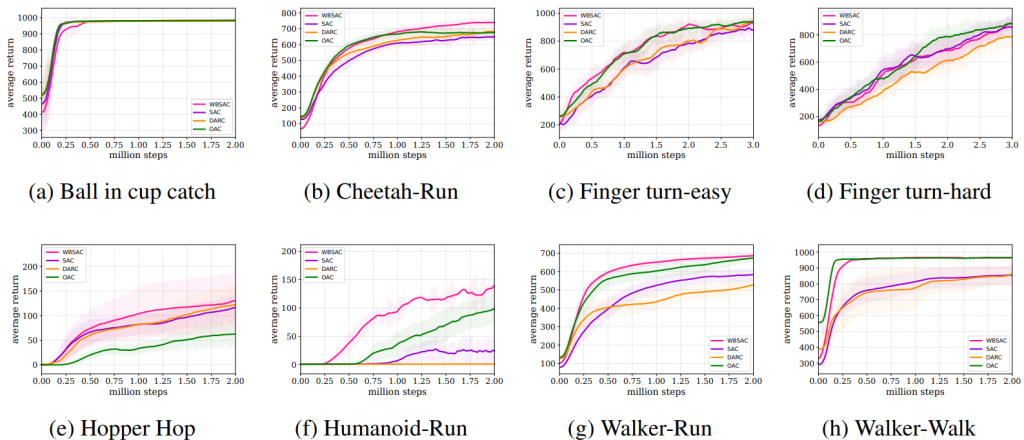
We evaluated the WBSAC algorithm on challenging continuous control benchmarks, specifically the MuJoCo and DeepMind control suit tasks. The results demonstrate that WBSAC consistently outperforms state-of-the-art baselines, including soft actor-critic (SAC) and double actors regularized critics (DARC), and optimistic actor-critic (OAC). As can be seen, our algorithm outperforms SAC and DARC in all four case studies of MuJoCo. Moreover, in all case studies except for Ant-v5, WBSAC achieves superior or comparable performance to OAC. In DeepMind control suit tasks, the results show that WBSAC outperforms the baselines and successfully solves the challenging humanoid-run task on which other methods fail. For more details, see WBSAC.
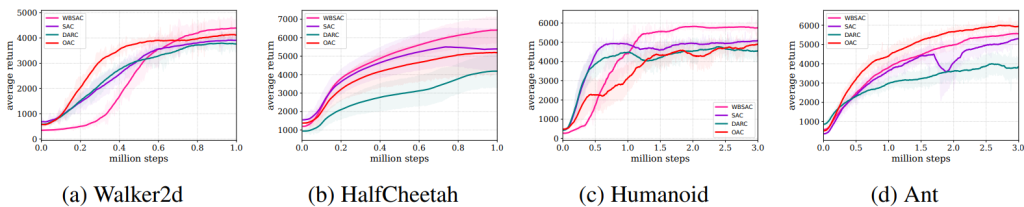
Performance comparison on MuJoCo environments